

It has been over a year since I have posted an update to “My Crusade for Agility”. In that time, there have been significant changes. The team has grown: we now have 5 full time developers. There have also been quite a few other changes:
- We are using dual machine pairing stations
- We are building software using a more service oriented approach
- We are building more rich client JavaScript applications
- We are placing more emphasis on integration testing
Dual Machine Pairing Stations
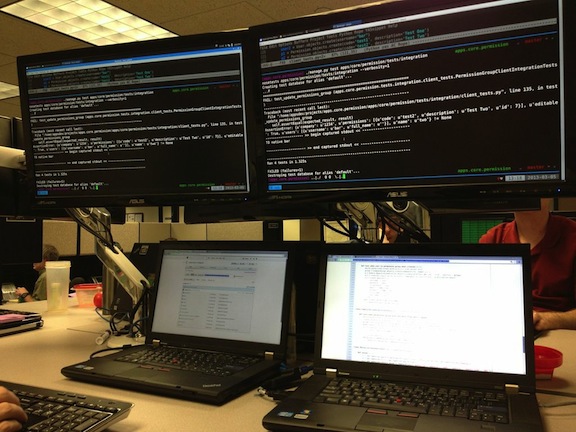
Hardware
- 2 - 22 inch monitors
- 2 - Laptops (Either a Lenovo running Mint or Ubuntu or a Macbook)
- 2 - Keyboards
- 2 - Mice
Setup
Each laptop has one external display. The displays are vertically positioned so that each person will have an upper and a lower display. Each keyboard / mouse combination controls only one of the two laptops. The external displays are typically a full screen terminal widow. Using SSH and Tmux, the terminal is a shared session that either person can interact with.
There are a lot of benefits that I have seen using a dual machine pairing station over a single machine pairing station. Our previous pairing stations consisted of a single machine with two mice and two keyboards. This worked very well, however there were some drawbacks. When there is only one machine it can only do one thing at a time. Only one person can be using the mouse or typing at a time. This can be an advantage because it forces both individuals to be fully engaged, however it also can prevent some very beneficial parallel work from being done. The best example that I have is when the driver is coding the navigator can be searching docs or writing some quick spike code. One last thing to note is that we really do not practice pairing with formal driver / navigator roles. The way that we pair is probably closer to ping pong pairing but not quite that strict. I think the best way to describe our method of pair programming would be to call it a discussion between two developers that results in software.
Service Oriented Approach
When we begin building our web based system in 2009, the plan was to build a web based replacement for our desktop based product. Somewhere along the line we realized that we had a suite of products to offer as well as integration between the products instead of just a single all-in-one product. The product suite approach has many advantages to both us and our customers, but I will not dive into that discussion right now.
Originally, we started with a single Django project. At this point we are up to 12 Django projects and 1 Flask project. In addition to the 13 deployable projects we also have 16 closed source libraries, 21 open source libraries, and quite a few other miscellaneous code bases for random other reasons. Just to throw out a few other random facts: we currently have 16 servers (3 on EC2 and the rest on our internal cloud) that we manage using Chef and we deploy our applications using Capistrano and capistrano-django.
Building software using a service oriented approach has a lot of benefits.
- Everyone is always working in a different repository, so you do not have to worry about running into merge conflicts (most of the time).
- Features can be deployed in isolation without having to take the entire system off line.
- Code bases are smaller and more single purposed (so easier to maintain)
- No huge build processes, since most code bases are relatively small
As we continue to go down the service oriented path I see more and more similarities between system architecture and object oriented design. That is probably a topic for another time.
Rich Client JavaScript
Building rich client applications using JavaScript really seems to fit very well with a service oriented architecture. There are so many benefits, again this is a whole topic by itself. There are a few specific benefits that I want to address.
-
No duplication between UI and API. This is something that we learned the hard way. Our first web service has an API and also has a user interface. The user interface is built using server side tools. The major down side to this is that when something changes we now have to update 2 things: the UI and the API. Because they are separate, they must be maintained in parallel. Using a client side JavaScript framework you just use the exact same API that is used everywhere else which means that when something changes only the API needs to be updated.
-
Fewer back-and-forth ajax trips. One sin that I have committed over and over is throwing a spinner up on the page while an ajax request is going back to the server to get some additional information. Multiple trips to the server is very common among most of our ajaxy applications. Using a client side MVC approach we are able to identify nearly all of the information we need up front, call the appropriate API and just change the page dynamically using the data that we have already cached on the client.
-
It makes so much more sense. The development process for building rich web applications is painful. Nearly any web developer will probably disagree, unless they have seen the light. Building client side applications in JavaScript is quite a bit simpler than rendering the client side application on the server. You can get an entire JavaScript MVC application up and running in the browser without a server at all. You can be testing it, using it (with fake data), and making UI tweaks without ever having to mess with a server or a database or any of that extra baggage. When you get right down to it none of those other things have anything to do with a UI in the first place.
There are a lot of people that groan and dislike JavaScript heavy applications, but the tools are here now. Building rich client applications in JavaScript is not only possible but pleasurable. The browser is a legitimate platform and the tools are great and constantly improving.
More Emphasis on Integration Testing
Integration testing was something that we have, for a very long time, done sparingly. There is a reason for this: it is hard and it is slow. Our main code base is nearing the 10,000 test mark, so having slow integration tests has always been something that we have frowned upon. At this point it takes nearly 3 minutes to run all 10,000 tests, and just about 1 minute when we run only the “fast” tests. (we flag “slow tests” so that we are not burdened with running all of them every time).
Now that we have so many different (and much smaller) code bases it is alright for us to have “slower” integration type tests because there are fewer total tests. My hope is that as our products grow we continue to make sure that each repository remains small and continues to have a single purpose which in turn will allow us to have a smaller number of overall tests in a single build. So far, I think we have done a good job but time will tell.
That is it for this update, there is a lot more to cover so stop back soon!